



Есть правильные и неправильные вопросы при продвижении. Неправильные – это что нам создать: группу или социальную страницу, в какую социальную сеть пойти. Правильные – чего мы хотим добиться.
DataRetriever — cервис для сбора и анализа данных из СМИ и социальных сетей

Это возможность отследить результаты рекламных кампаний и точнее реагировать на сообщения пользователей.
4 августа 2011
Это возможность отследить результаты рекламных кампаний и точнее реагировать на сообщения пользователей.
Когда вас пришла идея создать этот проект? Для чего он создавался? Кто целевая аудитория проекта?
Весной 2011 года мне пришла в голову идея создать собственный продукт для мониторинга блогов, сми и социальных сетей. Этот продукт был нужен самой компании для оценки своих рекламных кампаний, отклика на сообщения клиентов в блогах, форумах и социальных сетях. На рынке к тому моменту было несколько достаточно интересных проектов, как российиских, так и зарубежных, однако ни один из них не мог удовлетворить всем необходимым критериям:
Этот продукт был нужен самой компании для оценки своих рекламных кампаний, отклика на сообщения клиентов в блогах, форумах и социальных сетях. На рынке к тому моменту было несколько достаточно интересных проектов, как российиских, так и зарубежных, однако ни один из них не мог удовлетворить всем необходимым критериям:
• наличие демо версии;
• большой, пополняемый список источников;
• инсталлируемая версия;
• приемлемая цена;
В результате был решено создать такой продукт самим, и в течение нескольких месяцев система, получившая название DataRetriever, была разработана и запущена в эксплуатацию.
DataRetriever будет востребован среди специалистов по PR, маркетологов, SMO-оптимизаторов, пресс-аналитиков. Ценность его заключается в возможности отследить результаты рекламных кампаний и предоставить брендам возможность быстрее и точнее реагировать на сообщения пользователей и публикации в электронных средствах массовой информации.
Несколько слов о самом сервисе, как все устроено и что именно отслеживается?
С помощью сервиса можно находить упоминания в СМИ и социальных сетях — компаний, продуктов, людей и т.д., строить графики количества публикаций, проводить анализ источников, формировать отчеты, экспортировать данные в MS Office.
Базовые настройки предусматривают работу со следующими источниками:
1. Все СМИ, представленные в Интернете и доступные для обработки
поисковыми машинами
2. Крупные блогоплощадки: Livejournal, LiveInternet, Blogspot, Wordpress, и т.д.
3. Twitter
4. Социальные сети: Facebook, ВКонтакте
5. Flickr, Youtube
Причем список может дополняться и изменяться без ограничений. Отслеживаются как тексты, так и графические материалы и видео.
Рабочий процесс пользователя близок к работе с поисковой системой: надо задать список ключевых слов или фраз, и, спустя некоторое время (необходимое для проведения мониторинга), появляются первые результаты. Далее система продолжает мониторинг источников по заданным ключевым словам в автономном режиме, пополняя список результатов.
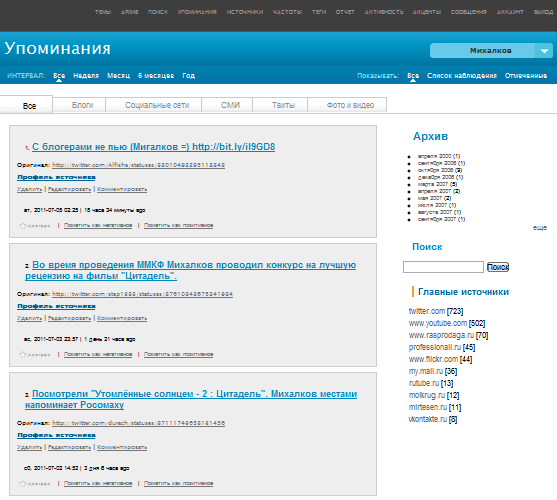
Поиск информации может производиться на нескольких языках. Система является самообучающейся: если в процессе мониторинга выявляются новые источники информации, они автоматически запоминаются, расширяется первоначальный список источников, и источник автоматически удаляется из списка, если пользователь удаляет ключевые слова, связанные с этим источником.
Полученную информацию можно обрабатывать. Для этого пользователю предоставляется набор инструментов для анализа количества публикаций во времени, выявления наиболее активных источников, определения тональности публикаций, составления отчетов и экспорта их в формат MS Office, а также средства коллективной работы (чат).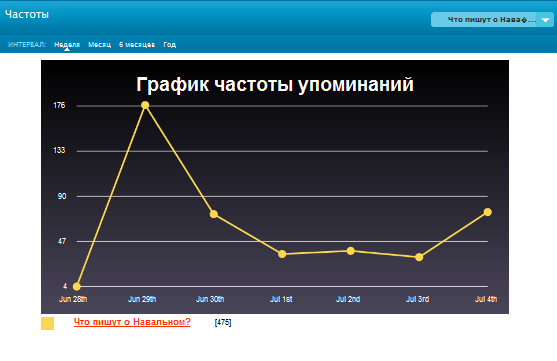 Какие дальнейшие планы?
Какие дальнейшие планы?
В данный момент DataRetriever существует в виде интернет-сервиса (демо версия), и в виде серверного приложения, распространяемого по лицензии GPL версии 3. Оба варианта снабжены пользовательским руководством.
Дальнейшие планы разработчиков заключаются в работе над улучшением качества поиска (более точный поиск упоминаний и отсеивание мусора),а также создании и запуске англоязычной версии сервиса, чтобы превратить DataRetriever в глобальный продукт.

Комментировать